5 - Muitas Variáveis e os Waffles Espúrios¶
Nosso objetivo nessa parte é começar o processo da construção de modelos de regressões múltiplas e, assim, também começaremos a criar as bases para o framework de inferências causais.
Para iniciarmos a discussão iremos introduzir um exemplo empírico, ou seja, um exemplo baseado na experiência e observações, sejam elas baseadas em algum método (metódicas) ou não.

Aula - Statistical Rethinking Winter 2019 Lecture 05
A waffle house é uma cadeia de restaurantes com mais de \(2000\) locais em \(25\) estados nos EUA (mapa amarelo abaixo). A maioria das suas localizações está no Sul do país e é um item da cultural e regional norte americana. (wikipedia). Uma das particularidades dessa rede de restaurantes é que eles trabalham 24 horas. Nunca fecham! Essa é a proposta de negócio deles.
Um outro fato importante e desagradável que se surge no sul dos EUA são os Furacões. Esses são causados pelas depressões tropicais climáticas do pais. Os restaurantes da rede Waffles são um dos únicos estabelecimentos que continuam abertos nesses períodos turbulentos. Exceto quando esses furacões atingem uma de suas lojas.
A rede é tão confiável que governadores dos EUA criaram o waffle house index, internamente na FEMA (agência federal de gestão de emergências). Usada como uma métrica informal com o nome da rede de restaurantes, pretendem determinar o efeito das tempestades, como uma escala auxíliar para o planejamento de recuperação de um desastre. (waffle house index)
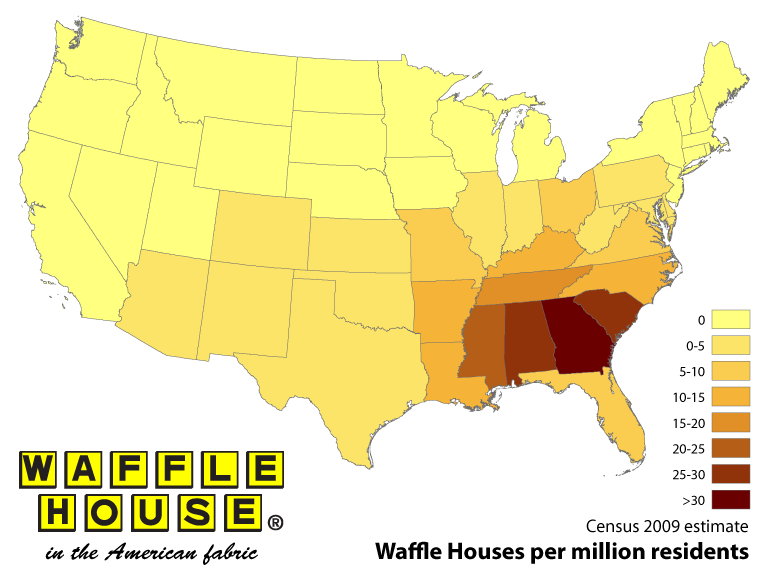
Imagem - https://www.scottareynhout.com/blog/2017/10/7/waffle-house-map
Além dos desastres naturais, existem também muitas outras coisas acontecendo em grande escala no sul dos EUA, tal como divórcios!
No gráfico abaixo temos a indicação da quantidade de divórcios nos EUA. Observe o sul do país e compare com o mapa acima.
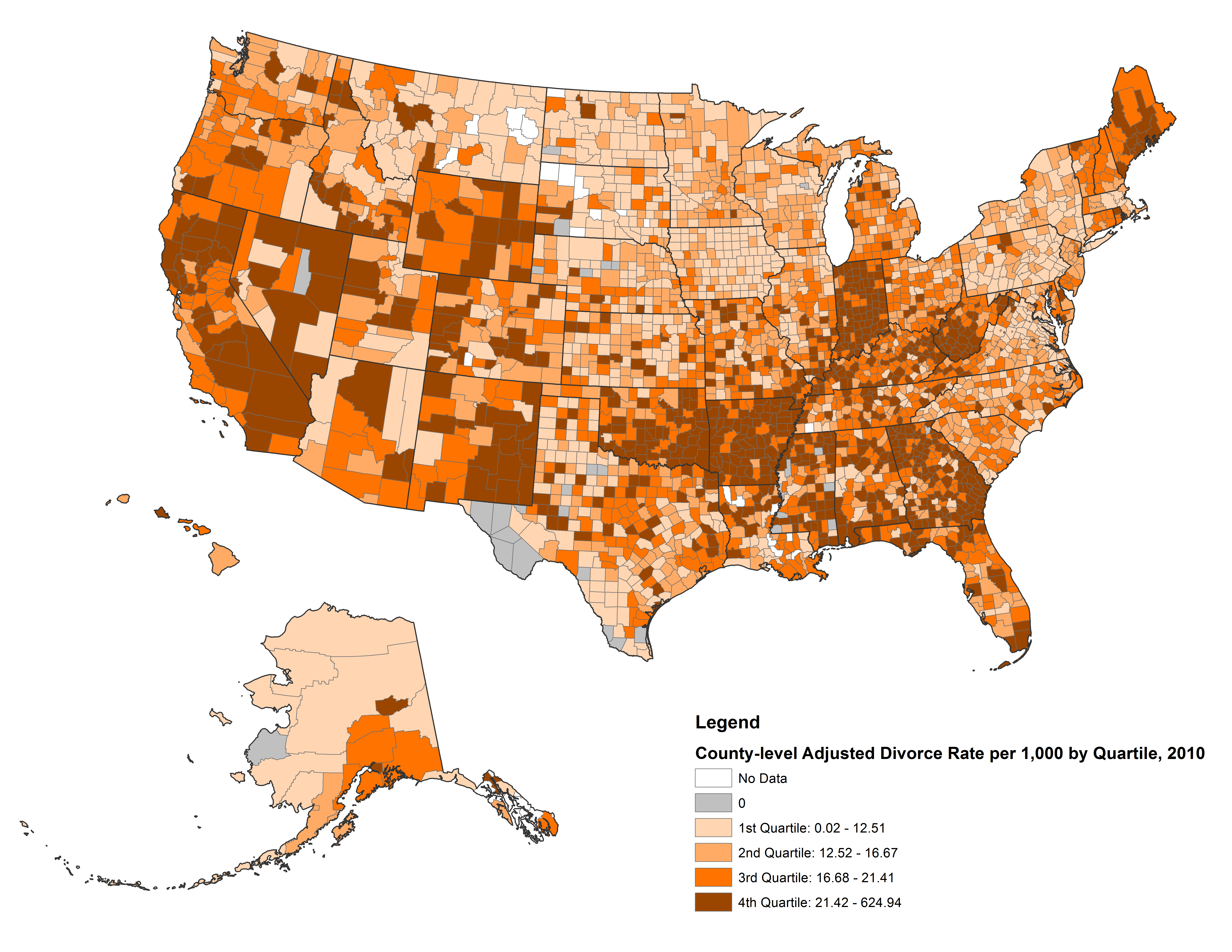
Imagem - https://www.bgsu.edu/ncfmr/resources/data/original-data/county-level-marriage-divorce-data-2010.html
Percebeu?
Em ambos os mapas existem uma grande concentração, no extremo do sul do mapa, de restaurantes da rede Waffle House e, subindo mais ao norte do país, temos quantidades cada vez menores. O mesmo ocorre no mapa das taxas de divórcios, quando olhamos para os mesmos locais no mapa.
Podemos então fazer uma estimativa: esses dados estão correlacionados entre si. E podemos nos ser levados a pensar que quanto maior a concentração de restaurantes na região maior seria seria a taxa de divórcios.
E por que isso acontece?
Pelo seguinte motivo: Por nada!
Isso mesmo, nada!!!
Não existe nada que tenha uma relação direta na qual a quantidade de restaurantes da rede em alguma determinada região influencie casais a brigarem e tomarem a decisão de se separar!
É estranho. É cômico. É intrigante. Isso é uma Correlação Espúria!
Correlações Espúrias¶
Essas são as correlações espúrias, ou seja, correlações sem certeza; que não é verdadeira nem real; é hipotética!
Muita coisa está relacionada com as outras no mundo real. Isso é a Natureza!
Por exemplo, se quisermos, por qualquer motivo que seja, arrumar um “argumento” para enfraquecer a imagem da rede Waffle House, “podemos” usar essas correlações espúrias com um dos argumentos. Assim, nós iriamos expor na mídia a seguinte manchete:
Breaking News:
Pesquisadores [da universidade xyz] indicam que: o aumento do número de restaurantes da rede Waffle House na região implica num aumento assustador no número de divórcios nessa mesma região!
Isso soa estranho, eu sei! Esse é apenas um exemplo extremo.
Mas, lá no fundo, esse tipo de pensamento não soa tão estranho no dia-a-dia…
Existem diversas correlações espúrias no mundo. Muita coisa tem correlação com muitas outras coisas.
Entretanto:
Essas correlações não implicam causalidade.
Mas para entendermos melhor, vamos ver mais alguns exemplos sobre essas correlações espúrias:
O consumo de queijo tem uma correlação de \(94.7\%\) com os acidentes fatais com o emaranhado do lençol de cama.
O consumo per capita de frango apresenta uma correlação de \(89\%\) com a importação de petróleo.
Os acidentes por afogamentos em piscina tem a correlação de \(66\%\) com o número de filmes lançados pelo Nicolas Cage, por ano. Veja graficamente essa correlação abaixo:
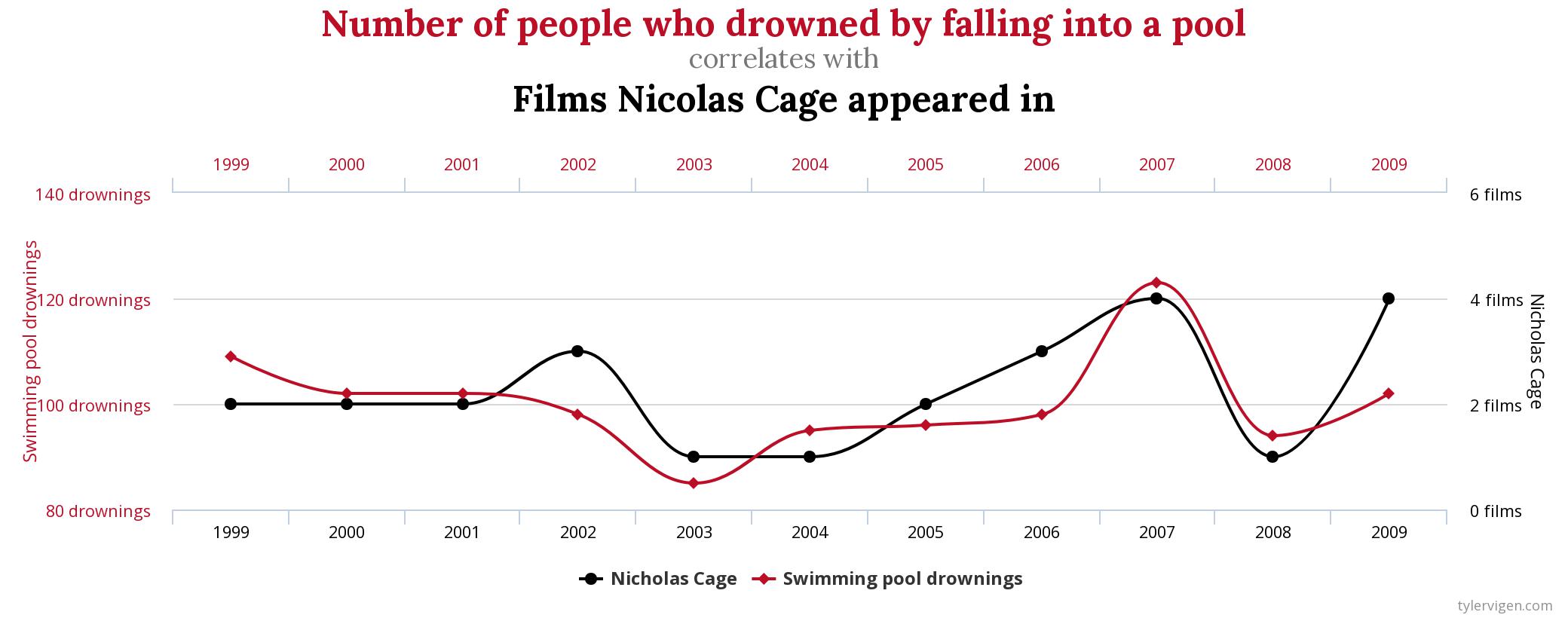
Percebeu?
Se o consumo de frango diminuísse, a importação provavelmente não sofreria nenhum impacto por essa causa. E, caso o consumo de queijo diminuir, também não haverá uma diminuição nos acidentes fatais das pessoas que estão dormindo em suas camas. E, como é esperado, se o Nicolas Cage se aposentar dos cinemas, os acidentes por afogamento continuarão constantes.
Tip
Correlação não implica causalidade!
Por fim, ter mais lojas da rede Waffle House não causa mais divórcios na região.
Mais correlações espúrias, tais como essas acima, podem ser encontradas no site do Tyler Vigen.
Entendido essa parte, vamos ao objetivo desse capítulo.
Regressão Múltiplas¶
Vamos ver como construir um modelo de regressão linear novamente. Mas dessa vez iremos ver também como se faz com múltiplas variáveis e quais são suas implicações.
Prós e contras das múltiplas variáveis:¶
A parte boa desse tipo de modelo é que as regressões múltiplas podem não só revelar correlações espúrias como também podem revelar associações escondidas que nós não faríamos normalmente, ou seja, não teríamos visto essas associações usando o modelo com uma simples variável preditora.
Mas, por outro lado, podemos também adicionar variáveis explicativas aos modelos que contenham correlações espúrias à regressão múltipla e, podem também, esconder as algumas das reais associações que existem.
Então, como essas coisas geralmente não são bem explicadas, vamos detalhar todo o processo de construção de uma regressão múltipla, a seguir.
Quando construímos um modelo usando uma regressão múltipla, nós devemos ter uma estrutura mais profusa para pensar sobre as nossas decisões. Apenas jogar todas as variáveis explicativas dentro da regressão múltipla, como usualmente é feito, é o segredo para o fracasso da análise e nós não queremos fazer isso!
Para isso precisamos de uma estrutura mais ampla e rica para conseguirmos pensar e tomar melhores decisões. Essa estrutura é o framework de inferência casual.
Nessa parte iremos aprender do básico sobre inferência casual:
Grafos acíclicos direcionados (DAGs - Directed acyclic graphs)
Fork, pipes, colliders…
Critério de Backdoor.
Já sabemos que o Waffle House não causam os divórcios. Mas o que causa os divórcios?
Já vimos no mapa acima que divórcios do sul do país tem uma taxa bem mais alta do que no restante mais ao norte. Existem muitos esforços para tentar identificar as causas e as taxas de divórcios. Sabemos que no sul tem uma predominância religiosa quando comparada ao restante do país. Isso deixa os cientistas com certas desconfianças.
Existem assim muitas coisas que estão correlacionadas com a taxa de divórcios. Uma delas é a taxa de casamentos. Também podemos usar essas informações para cada um dos outros \(50\) estados do país. Todos eles têm uma correlação positiva da taxa de casamentos com a taxa de divórcios.
Um ponto importante nessa correlação é que só pode acontecer um divórcio se houver o casamento!
Mas a correlação entre essas taxas podem ser também correlações espúrias. Assim como a correlação entre homicídos e divórcios são uma correlação espúria.
Pois uma taxa alta de casamentos pode indicar que a sociedade vê o casamento de modo favorável e isso pode significar taxas de divórcios mais baixas. Não necessariamente faz sentido, mas pode ser que as taxas de casamentos e de divórcios sejam correlações espúrias também.
Note
Correlação não implica Causalidade
Causalidade não implica Correlação
Causalidade implica em correlação condicional
Assim, precisamos mais do que apenas simples modelos! É necessário um estrutura mais robusta.
Mas, o que causa os divórcios?
Vamos descobrir isso…
Existe outra variável que também é correlacionada com a variável taxa de divórcio, é a variável idade mediana das pessoas que se casam, em cada estado. Mas diferente da taxa de casamento, essa variável apresenta uma correlação negativa.
import numpy as np
import pandas as pd
import stan
import nest_asyncio
import matplotlib.pyplot as plt
plt.style.use('default')
# Definindo o plano de fundo cinza claro para todos os gráficos feitos no matplotlib
plt.rcParams['axes.facecolor'] = 'lightgray'
# Desbloqueio do asyncIO do jupyter
nest_asyncio.apply()
def HPDI(posterior_samples, credible_mass):
# Calcula o maior intervalo de probabilidades a partir de uma amostra
# Fonte: https://stackoverflow.com/questions/22284502/highest-posterior-density-region-and-central-credible-region
sorted_points = sorted(posterior_samples)
ciIdxInc = np.ceil(credible_mass * len(sorted_points)).astype('int')
nCIs = len(sorted_points) - ciIdxInc
ciWidth = [0]*nCIs
for i in range(0, nCIs):
ciWidth[i] = sorted_points[i + ciIdxInc] - sorted_points[i]
HDImin = sorted_points[ciWidth.index(min(ciWidth))]
HDImax = sorted_points[ciWidth.index(min(ciWidth))+ciIdxInc]
return(HDImin, HDImax)
# ====================================
# Lendo os dados da Waffle House
# ====================================
df = pd.read_csv('./data/WaffleDivorce.csv', sep=';')
df.head()
| Location | Loc | Population | MedianAgeMarriage | Marriage | Marriage SE | Divorce | Divorce SE | WaffleHouses | South | Slaves1860 | Population1860 | PropSlaves1860 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alabama | AL | 4.78 | 25.3 | 20.2 | 1.27 | 12.7 | 0.79 | 128 | 1 | 435080 | 964201 | 0.45 |
| 1 | Alaska | AK | 0.71 | 25.2 | 26.0 | 2.93 | 12.5 | 2.05 | 0 | 0 | 0 | 0 | 0.00 |
| 2 | Arizona | AZ | 6.33 | 25.8 | 20.3 | 0.98 | 10.8 | 0.74 | 18 | 0 | 0 | 0 | 0.00 |
| 3 | Arkansas | AR | 2.92 | 24.3 | 26.4 | 1.70 | 13.5 | 1.22 | 41 | 1 | 111115 | 435450 | 0.26 |
| 4 | California | CA | 37.25 | 26.8 | 19.1 | 0.39 | 8.0 | 0.24 | 0 | 0 | 0 | 379994 | 0.00 |
# ============================================
# Plotando os dados das taxas de divórcios
# ============================================
fig, [ax1, ax2] = plt.subplots(1, 2, figsize=(17, 9))
plt.suptitle('Associações Espúrias?')
ax1.scatter(df.Marriage.values ,df.Divorce.values)
ax1.grid(ls='--', color='white', linewidth=0.4)
ax1.set_xlabel('Taxa de Casamento')
ax1.set_ylabel('Taxa de Divórcio')
ax2.scatter(df.MedianAgeMarriage.values ,df.Divorce.values)
ax2.grid(ls='--', color='white', linewidth=0.4)
ax2.set_xlabel('Mediana da Idade dos Noivos')
ax2.set_ylabel('Taxa de Divórcio')
plt.show()
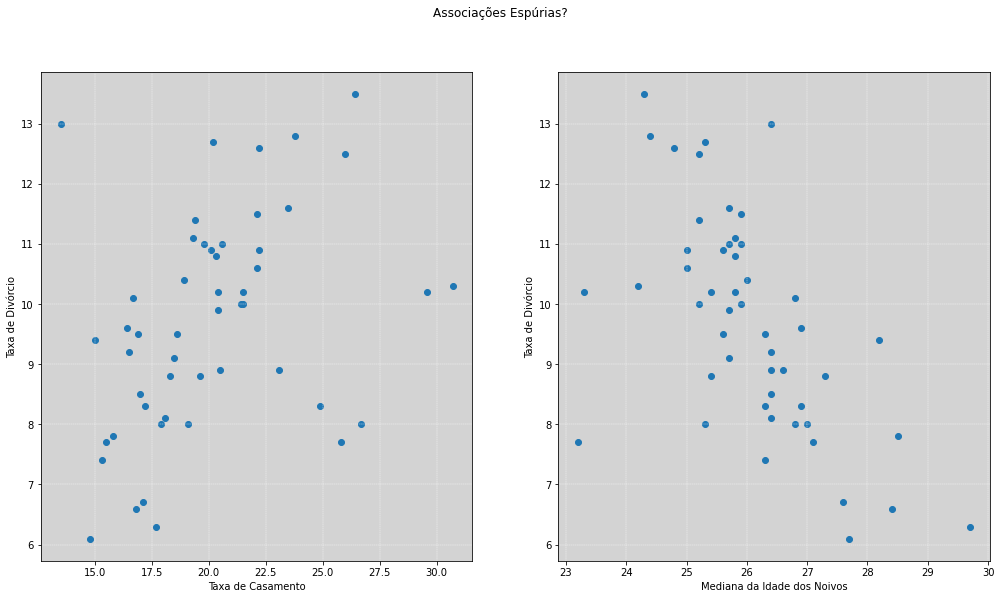
Vamos construir modelos lineares simples para os dois gráficos acima.
# ========================================================
# Construindo um modelo linear simples:
#
# taxa de divórcio ~ alpha + beta * taxa_casamento
# ========================================================
divorce_model1 = """
data {
int N;
vector[N] divorce_rate;
vector[N] marriage_rate;
}
parameters {
real alpha;
real beta;
real<lower=0, upper=50> sigma;
}
model {
divorce_rate ~ normal(alpha + beta * marriage_rate, sigma);
}
"""
my_data = {
'N': len(df.Divorce),
'marriage_rate': df.Marriage.values,
'divorce_rate': df.Divorce.values,
}
posteriori1 = stan.build(divorce_model1, data=my_data)
fit1 = posteriori1.sample(num_chains=4, num_samples=1000)
alpha_1 = fit1['alpha'].flatten()
beta_1 = fit1['beta'].flatten()
sigma_1 = fit1['sigma'].flatten()
# ==============================================================
# Construindo um modelo linear simples:
#
# taxa divorcio ~ alpha + beta * mediana da idade dos noivos
# ==============================================================
stan_model2 = """
data {
int N;
vector[N] divorce_rate;
vector[N] median_age_marriage;
}
parameters {
real alpha;
real beta;
real<lower=0, upper=50> sigma;
}
model {
divorce_rate ~ normal(alpha + beta * median_age_marriage, sigma);
}
"""
my_data = {
'N': len(df.Divorce),
'divorce_rate': df.Divorce.values,
'median_age_marriage': df.MedianAgeMarriage.values,
}
posteriori2 = stan.build(stan_model2, data=my_data)
fit2 = posteriori2.sample(num_chains=4, num_samples=1000)
alpha_2 = fit2['alpha'].flatten()
beta_2 = fit2['beta'].flatten()
sigma_2 = fit2['sigma'].flatten()
# ====================================================================
# Plotando os dados das taxas de divórcios e suas estimativas médias
# ====================================================================
fig, [ax1, ax2] = plt.subplots(1, 2, figsize=(17, 9))
plt.suptitle('Associações Espúrias?')
# Calculando as regiões de HPDI para mu - Taxa de casamentos com 0.92 de credibilidade
range_mu = np.sort(df.Marriage)
posteriori_mu_aux = np.array([[alpha_1 + beta_1 * marriage for marriage in range_mu]])[0]
posteriori_mu_HPDI = np.array([[HPDI(posteriori_marriage, 0.92) for posteriori_marriage in posteriori_mu_aux]])[0]
# Gráfico de Divórcio x Casamento
ax1.scatter(df.Marriage.values ,df.Divorce.values)
ax1.fill_between(range_mu,
posteriori_mu_HPDI[:, 0], posteriori_mu_HPDI[:, 1],
color='gray', alpha=0.4)
ax1.plot(df.Marriage.values,
alpha_1.mean() + beta_1.mean() * df.Marriage.values,
color='black')
ax1.grid(ls='--', color='white', linewidth=0.4)
ax1.set_xlabel('Taxa de Casamento')
ax1.set_ylabel('Taxa de Divórcio')
ax1.set_title('Correlação Positiva \n Espúria?')
# ------------
# Calculando as regiões de HPDI para mu - Mediana para idade de casamentos com 0.92 de credibilidade
range_mu = np.sort(df.MedianAgeMarriage)
posteriori_mu_aux = np.array([[alpha_2 + beta_2 * mediaAgeMarriage for mediaAgeMarriage in range_mu]])[0]
posteriori_mu_HPDI = np.array([[HPDI(posteriori_mediaAgeMarriage, 0.92) for posteriori_mediaAgeMarriage in posteriori_mu_aux]])[0]
# Gráfico de Divórcio x Mediana da Idade dos Casamentos
ax2.scatter(df.MedianAgeMarriage.values ,df.Divorce.values)
ax2.fill_between(range_mu,
posteriori_mu_HPDI[:, 0], posteriori_mu_HPDI[:, 1],
color='gray', alpha=0.4)
ax2.plot(df.MedianAgeMarriage.values,
alpha_2.mean() + beta_2.mean() * df.MedianAgeMarriage.values,
color='black')
ax2.grid(ls='--', color='white', linewidth=0.4)
ax2.set_xlabel('Mediana da Idade dos Noivos')
ax2.set_ylabel('Taxa de Divórcio')
ax2.set_title('Correlação Negativa \n Espúria?')
plt.show()
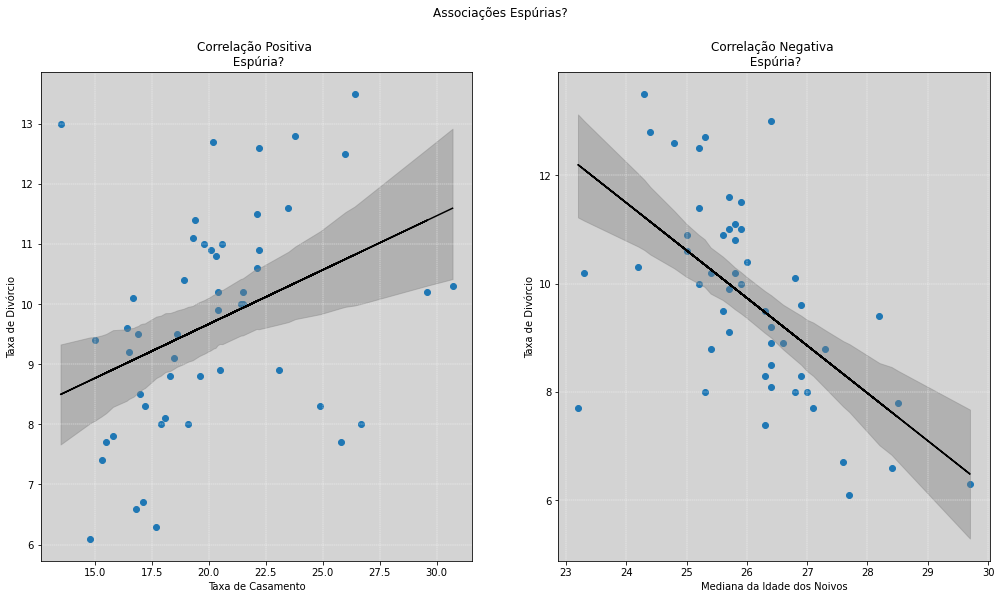
Observando os dois gráficos acima, quais dessas correlações são causas plausíveis?
No gráfico da esquerda, sabemos que a taxa de casamento tem uma associação direta com a taxa de divórcio, pois, para se divorciar é necessário antes ter casado. Mas essa interpretação dos fatos pode estar contaminada pelo nosso senso comum e, assim, uma associação espúria, nos seria válida. Um dos motivos pra isso acontecer é que em locais que possuem maiores incentivos religiosos e podem implicar em maiores incentivos para casamentos, podendo, assim, não haver uma causalidade direta com o divórcio.
Já no gráfico à direita, a taxa de divórcio está associada com mediana das idades dos noivos, nos apresentando uma associação negativa. Isso pode nos levar a pensar que jovens, ao se casarem, tomam decisões muito emotivas e que isso também levaria a altas taxas de divórcios. Ou pode ser que essa seja uma associação espúria e nossas hipóteses e nosso senso comum não tenha sentido.
Assim, mesmo que nossas justificativas sejam bastante verossímeis a respeito do comportamento da Natureza do evento, não podemos afirmar que essas associações não sejam espúrias.
Se a identificação de associações espúrias, como no exemplo de filmes do Nicolas Cage, pareciam óbvias de serem identificadas, agora, essas não parecem ser tão simples de perceber sua veracidade.
Portanto, é necessário construirmos um ferramental que nos permita identificar com mais facilidade e, com um maior grau de certeza, se essas associações são reais ou são espúrias.
O que queremos fazer agora é colocar essas duas variáveis no mesmo modelo e entender o que isso faz e por que nos revela, quase certamente, que determinada variável é uma impostora.
Múltiplas causas de divórcios¶

{kind=link}
Como entender o mecanismo das Causas Naturais de divórcio numa cidade grande
O que nós queremos saber é qual o valor de uma variável preditora, uma vez que nós conhecemos os valores das outras variáveis preditoras corretamente?
Todas variáveis preditoras são ,em alguma extensão, correlacionadas com as outras variáveis preditoras e, também, com a variável resposta. Entretanto, elas têm correlações parciais que são reveladoras de informações adicionais dessa estrutura de correlação.
Para entendermos melhor, vamos exemplificar com nosso exemplo sobre divórcios.
Nós gostariamos de aprender mais sobre o valor da taxa de casamentos, uma vez que já conhecemos a mediana da idade da taxa dos noivos.
Entendendo os grafos um pouco mais perto.¶
DAG’s são o acrônimo para a expressão inglês Directed Acyclic Graph, o que é portugês é conhecido como Grafos Acíclicos Direcionados (ver mais em wikipedia).
# =======================================
# Construindo o desenho de um DAG
# =======================================
# -----------------------------------------------------
# Obs: Os próximos grafos irei esconder os códigos,
# para ficar visualmente melhor. Mas, se quiser,
# os códigos podem ser encontrados no github.
# -----------------------------------------------------
plt.figure(figsize=(17, 7))
plt.xlim(0, 1)
plt.ylim(0, 1)
size=40
plt.annotate('A', (0.2, 0.8), fontsize=size)
plt.annotate('M', (0.8, 0.8), fontsize=size)
plt.annotate('D', (0.495, 0.2), fontsize=size)
plt.title('Grafo dos Divórcios')
# Edge: M <---> D
plt.annotate("",
xytext=(0.79, 0.79), xy=(0.53, 0.265) ,
arrowprops=dict(arrowstyle="-|>, head_width=1, head_length=1.2"))
# Edge: A <---> M
plt.annotate("",
xytext=(0.24, 0.82), xy=(0.77, 0.82),
arrowprops=dict(arrowstyle="-|>, head_width=1, head_length=1.2"))
# Edge: A <---> D
plt.annotate("",
xytext=(0.24, 0.77), xy=(0.48, 0.26),
arrowprops=dict(arrowstyle="-|>, head_width=1, head_length=1.2"))
# Remover os valores dos eixos
plt.yticks([])
plt.xticks([])
plt.show()
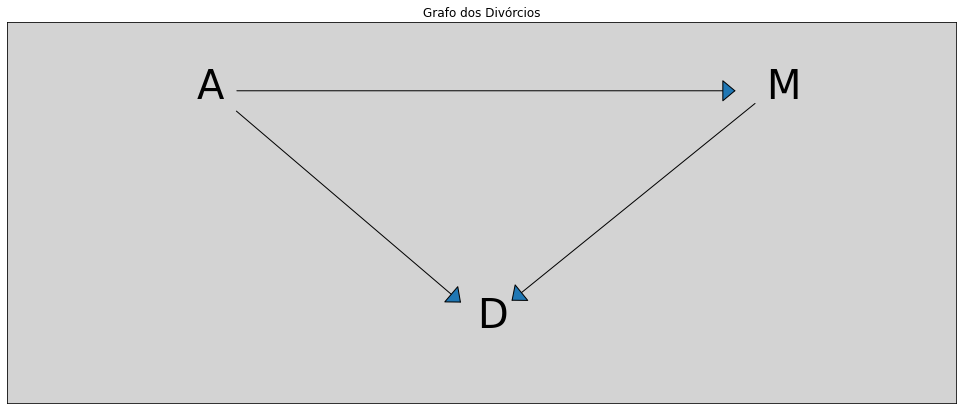
DAG’s são ferramentas heurísticas usadas no framework de inferências causais. Elas não como ferramentas mecânicas analíticas que já vimos, mas são incrivelmente úteis para nos auxiliar a pensar melhor e eventualmente também nos permite entender muito melhor os modelos mecânicos.
As setas do DAG apontam apenas em uma direção e essa direções indica uma relação de causalidade entre as variáveis analisadas, ou seja, indica que uma variável tem influência direta sobre a outra.
A ausência de ciclos significa que não existem loops na causalidade. Mas esses loops podem acontecer sobre o tempo, o que tornaria a análise também uma série temporal!
A representação desses problemas reais em estruturas como DAG’s podem ser, realmente, muito grandes. Pois, assim, podemos descrever a estrutura no tempo \(T\), \(\{T_1, T_2, ...\}\), e assim por diante.
Nós, normalmente rotulamos os grafos por dois nomes: nós (nodes) e arestas (edge). (Iremos aqui, por conveção, usar os nomes em inglês.)
Note
Os nodes (nós) são as variáveis. Já os edges (as arestas) representam a relação causal entre os nodes.
As associações que foram levadas em consideração, podem ser incluídas dentro dos modelos de redes bayesianas, que são considerados parte do conjunto de ferramentas de Machine Learning. Esses modelos também não levam em consideração a causalidade, pois não existe um mecanismo interno nesses modelos que leve em consideração a direção da causalidade.
Já nos DAG’s, tal mecanismo, existe!
Note
Esse mecanismo nos permite a capacidade de enxergar, através das lentes probabilísticas, a influência da causa e efeito em diferentes eventos! Isso não é medir uma associação. É uma medida para a causalidade!
E isso, faz toda a diferença!
Também veremos qual é a diferença entre as duas abordagens comnetadas…
Bons Grafos¶
Queremos saber a diferença entre esses dois grafos abaixo. O da esquerda tem um caminho direto de \(A <-> M <-> D\) e, no outro gráfico, uma suposição de que temos que a relação causal entre a taxa de casamento (\(M\)) e a taxa de divórcio (\(D\)) não existe mais.
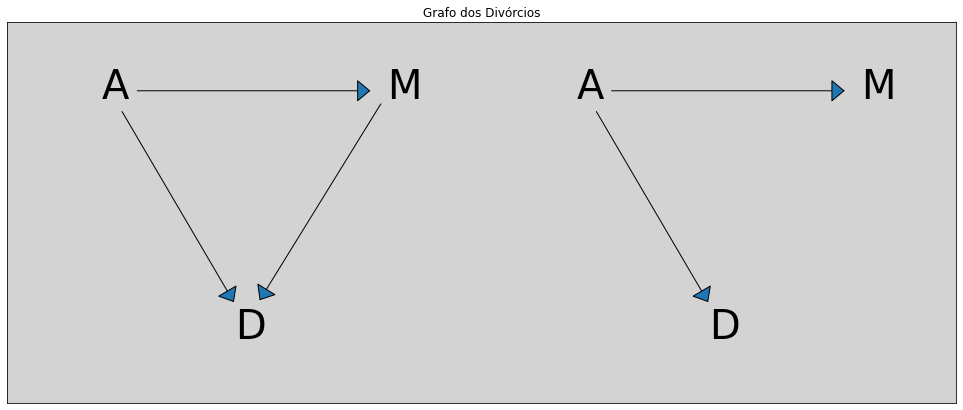
Regressões Lineares, em princípio, podem nos dizer a diferença entre essas duas coisas. Mas uma regressão bivariada já não pode mais. Elas podem nos dar apenas algum conhecimento da associação entre casamentos e divórcios, mas não podem nos dizer qual a diferença entre esses dois *DAG's* acima.
Mas, porque não?
Por que, A tem influência tanto na taxa de casamentos (\(A <-> M\)) quanto em D (\(A <-> D\)), isso gera uma correlação entre os eventos taxa de casamento (\(M\)) e taxa de divórcio (\(D\)), mesmo que uma não influencie na outra, como no gráfico à direita. (Elegante essa explicação, hein!)
É um modo bonito de dizer:
Warning
Correlação não é Casualidade!
Essa mesmo estrutura do DAG’s, pode ser modelada com as correlações espúrias do início do capítulo, waffle House vs taxa de divórcios

A correlação que existe entre essas duas variáveis como foi visto anteriormente, tem sua origem na causa de algum outro evento que não conhecemos, rotulado por (\(?\)). Só sabemos que seu comportamento tem uma influência direta sobre a magnitude do efeito dos divórcios e da quantidade de lojas da rede de restaurantes tem por região.
Então, se estamos tentando medir a ligação entre a taxa de casamentos (\(M\)) e a taxa de divórcios (\(D\)) usando, como sugestão, a estrutura o grafo da direita (da figura acima), teremos uma grande confusão. Pois mais adiante uma definição melhor sobre essa confusão.
Vamos rotular essa estrutura com a seguinte notação:
Significa que podemos conhecer a associação que \(M\) e \(D\) tem entre si, (\(M <-> D\)), condicionado (\(|\), caracter chamado de pipe) a \(A\).
Quando conhecemos o valor de \(A\), então eu tenho um valor extra, uma associação externa, entre as duas variáveis. E é isso que a regressão múltipla pode pode nos dizer.
Onde:
\(D_i\): Taxa de divórcio
As taxas médias dos casamentos:
\(\beta_M\): A ‘peso’ da taxa de casamentos
\(M_i\): A taxa média de casamentos
As as medianas das idades nos casamentos:
\(\beta_A\): A ‘peso’ da mediana das idades dos casamentos
\(A_i\): Mediana das idades dos casamentos
Podemos ver que esse modelo tem uma certa diferença dos modelos que vimos anteriormente. Existe um \(\beta\) para cada uma das variáveis preditoras.
Essa regressão linear, é um tipo especial de rede bayesiana, associa a variável resposta (\(D_i\)) a uma distribuição gaussiana. E sua média (\(\mu_i\)) é dada pela variáveis já conhecidas e um desvio padrão (\(\sigma\)).
Então, nossa média será descrita como \(\mu_i\), onde \(i\), significa que condicionaremos os valores de \(\mu_i\) para cada \(i\). Aqui, no exemplo, cada \(i\) indica um novo estado do sul dos EUA. E, assim, cada condicionamento será descrito pelos ‘pesos’ multiplicado as suas próprias variáveis preditoras.
Prioris¶
Agora, nós iremos padronizar a variável taxa de divórcio (\(D_i\)), a variável taxa de casamento (\(M_i\)) e também a variável mediana das idades dos casamentos.
Assim, como esperamos, podemos escrever a priori para \(\alpha\) da seguinte forma:
Pois esperamos que \(\alpha\) esteja próximo de zero!
E as prioris para os \(\beta\)’s da seguinte forma:
Pois todos os valores foram padronizados, e assim esperamos que a estimativa à priori seja próxima de zero.
# =============================
# Padronizando as variáveis
# =============================
M_stdr = (df.Marriage - df.Marriage.mean())/df.Marriage.std()
D_stdr = (df.Divorce - df.Divorce.mean())/df.Divorce.std()
A_stdr = (df.MedianAgeMarriage - df.MedianAgeMarriage.mean())/df.MedianAgeMarriage.std()
# ===========================================================
# Priori preditiva para Mediana das Idades dos Casamentos
# ===========================================================
range_A = np.linspace(A_stdr.min(), A_stdr.max()) # Range de valores da média de idade dos casamentos padronizados
qtd_amostras = 50 # Quantidade de amostras da priori preditiva
# Amostrando os valores de 𝜇𝑖 da priori
𝛼 = np.random.normal(0, 0.2, qtd_amostras)
𝛽_A = np.random.normal(0, 0.5, qtd_amostras)
𝜎 = np.random.exponential(1, qtd_amostras) # Priori 𝜎 ~ Exp(1)
# ========================================
# Gráfico da Priori Preditiva para 𝜇𝑖
# ========================================
𝜇 = [ 𝛼 + 𝛽_A * A_i for A_i in range_A ] # Calculando 𝜇𝑖 = 𝛼 + 𝛽𝐴 * 𝐴𝑖, para todo 𝐴𝑖
# Plotando o gráfico
plt.figure(figsize=(17, 9))
# Relembrando o DAG: A <-> D!
# Plotando as retas da posteriori para 𝜇𝑖
plt.plot(range_A, 𝜇, color='darkblue', linewidth=0.2)
plt.title("Priori Preditiva de $\mu_i$")
plt.xlabel("( $A$ ) Média das Idades dos Casamentos (padronizadas)")
plt.ylabel("( $D$ ) Taxa de Divórcio (padronizadas)")
plt.grid(ls='--', color='white', alpha=0.4)
# Ajustando os limites da visuzalização do gráfico.
plt.ylim((-2, 2))
plt.xlim((-2, 2))
plt.show()
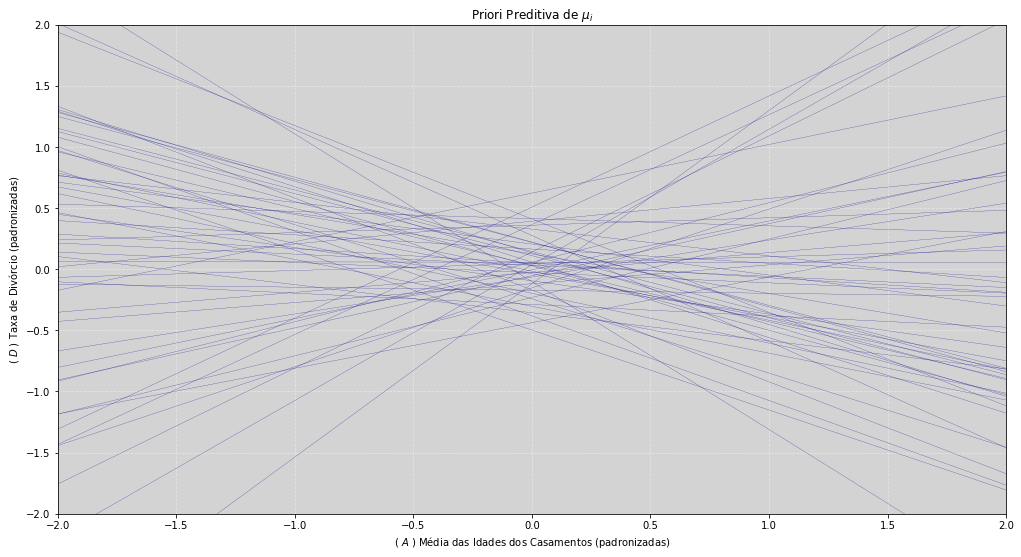
Temos no gráfico acima a representação da nossa distribuição à priori do modelo de regressão linear. Sorteamos \(50\) linhas dessa distribuição. Essa é a distribuição à priori preditiva de \(\mu_i\). Ou seja, isso é oque nosso modelo pensa sobre o problema, antes de darmos os dados à ele.
Temos que sempre fazer a simulação da priori preditiva. Só assim será possível entender uma importante característica presente em todos os modelo. Temos observar se a amplitude da priori faz sentido. Quando nós dermos os dados para o modelo, é necessário que as estimativas do modelo resida sobre distribuição à priori. Caso contrário, teremos uma priori ruim. Em cenários mais simples, e com muitos dados, esse efeito pode até passar despercebido e ajustar bem. Porém em cenários mais complexos, uma priori ruim poderá ser desastrosa!
Note
Sempre verifique a priori.
Vamos andar pelo gráfico para entendermos melhor suas partes. Iniciando pela Média das Idades dos Casamentos padronizada ($A$ padronizada) que é uma gaussiana, centrada em \(0\) e com desvio padrão\(\frac{1}{2}\):
No gráfico nós estamos observando todos os valores dentro do intervalo \([-2, \mbox{ } 2]\). Esse intervalo corresponde ao \(2^o\) desvio padrão! Isso deve corresponder a grande maioria dos casos que os valores da Mediana das Idades dos Casamentos (padronizadas) irá ocorrer.
Esse pensamento também é válido para a variável Taxa de Divórcio ($D$ padronizada). Seus valores também estão delimitados pelo intervalo \([-2, \mbox{ } 2]\), representando o \(2^o\) desvio padrão.
Esse modelo nos diz é qual a taxa de divórcio padronizada,(\(D\)), que é uma variável z-score, quando já conhecemos os valores da Média das Idades dos Casamentos (\(A\)), que também está padronizada (outra z-score). Assim temos duas variáveis padronizadas, z-scores, explicando uma à outra.
Agora, se as linhas da regressão linear não morar no espaço delimitado pela priori, então a escolhemos uma priori ruim! Por que isso é impossível! Se após dermos os dados pra o modelo, a inclinação da curva for maior que a delimitada pela região da priori, temos uma priori ruim.
Ainda podemos discutir se a escolha da priori irá governar todo o range da taxa de divóricio. Provavelmente não é verdade. Em capítulos posteriores, quando falarmos sobre overfitting (ou em português, teremos um sobreajuste). Isso acontece pois a priori não é apertada o suficiente para trabalharmos segurança. Nesse caso podemos pensar em prioris flat, que podem ser justificada cientificamente, tal como uma priori flat implícita nas análises frequentistas.
Nosso modelo¶
Esse é nosso modelo, descrito na primeira linha. Na segunda linha temos dois termos lineares, lembrando que o termo linear significa aditivo. Esses dois termos irá gerar um plano. A seguir, teremos nossas prioris. Um destaque para a priori do \(\sigma\), de agora em diante não vamos mais usar \(Uniform\) mas sim a distribuição \(Exponential\), pois ela tem boas propriedades. Falaremos mais sobre isso adiante.
O uso da distribuição \(Exponential\) como priori para \(\sigma\) tem vantagens tais como, sempre tem valores positivos, para valores maiores a sua probabilidade decresce e para defini-lá precisamos indicar qual será seu valor médio.
# =====================================
# Estimando o modelo linear proposto
# =====================================
stan_model_divorce = """
data {
int N;
vector[N] divorce_rate;
vector[N] marriage_rate;
vector[N] median_age;
}
parameters {
real alpha;
real beta_M;
real beta_A;
real<lower=0> sigma;
}
model{
alpha ~ normal(0, 0.2);
beta_M ~ normal(0,0.5);
beta_A ~ normal(0, 0.5);
sigma ~ exponential(1);
divorce_rate ~ normal(alpha +
beta_M * marriage_rate +
beta_A * median_age,
sigma);
}
"""
my_data = {
'N': len(D_stdr.values),
'divorce_rate': D_stdr.values,
'marriage_rate': M_stdr.values,
'median_age': A_stdr.values
}
posteriori_divorce = stan.build(stan_model_divorce, data=my_data)
fit_divorce = posteriori_divorce.sample(num_chains=4, num_samples=1000)
alpha = fit_divorce['alpha'].flatten()
beta_M = fit_divorce['beta_M'].flatten()
beta_A = fit_divorce['beta_A'].flatten()
sigma = fit_divorce['sigma'].flatten()
# Iremos usar esses valores mais tarde nesse material, quando formos fazer a verificação.
# Assim,irei renomear as variáveis da posteriori.
alpha_check = fit_divorce['alpha'].flatten()
beta_M_check = fit_divorce['beta_M'].flatten()
beta_A_check = fit_divorce['beta_A'].flatten()
sigma_check = fit_divorce['sigma'].flatten()
def resume_posteriori(var, confidence_HPDI=0.93, rounded=2):
"""
Return the summary of posteriori data
"""
posteriori = []
confi_HPDI = HPDI(var, confidence_HPDI)
posteriori.append(var.mean())
posteriori.append(var.std())
posteriori.append(confi_HPDI[0])
posteriori.append(confi_HPDI[1])
return np.round(np.array([posteriori]), rounded)[0]
def describe_posteriori(vars_post, confidence_HPDI=0.93, plot=True):
post = []
for var_ in vars_post:
post.append(resume_posteriori(eval(var_), confidence_HPDI))
hpdi_min_label = str(100 * round(1 - confidence_HPDI, 3)) + '%'
hpdi_max_label = str(100 * round(confidence_HPDI, 3)) + '%'
post = pd.DataFrame(post,
index=vars_post,
columns=['Mean', 'Std', hpdi_min_label, hpdi_max_label])
if plot:
plt.figure(figsize=(17, len(post) + 1))
plt.title('Estimativas das Posterioris')
min_axis_ = post.iloc[:, 2:4].min().min()
max_axis_ = post.iloc[:, 2:4].max().max()
for i in range(len(post)):
plt.plot([min_axis_*1.5, max_axis_*1.5], [i, i], ls='--', color='gray')
plt.plot([post.iloc[i, 2], post.iloc[i, 3]], [i, i], color='blue')
plt.plot(post.iloc[i, 0], i, 'ko')
plt.annotate(post.index[i], (min_axis_*1.5, i+0.2), color='blue')
if min_axis_ < 0 and max_axis_ > 0:
plt.axvline(0, ls='--', color='red', alpha=0.6)
plt.ylim((-1, len(post)+1))
plt.grid(ls='--', color='white', alpha=0.4)
ax = plt.gca()
ax.axes.yaxis.set_visible(False)
plt.show()
return post
# =====================================
# Descrevendo os dados da posteriori
# =====================================
vars_post = ['alpha', 'beta_M', 'beta_A', 'sigma']
describe_posteriori(vars_post, 0.945, plot=False)
| Mean | Std | 5.5% | 94.5% | |
|---|---|---|---|---|
| alpha | -0.00 | 0.10 | -0.18 | 0.20 |
| beta_M | -0.06 | 0.16 | -0.38 | 0.23 |
| beta_A | -0.61 | 0.16 | -0.91 | -0.29 |
| sigma | 0.83 | 0.09 | 0.67 | 0.99 |
As informações da tabela acima contém um resumo das posterioris estimadas. Como esperado \(\alpha\) tem a média \(0\). Pois tinha que ser assim conforme a construção do nosso modelo.
Já a estimativa para do \(\beta_M\), taxa de casamento, é levemente negativa e o desvio padrão está entre \(2\) a \(3\) vezes a sua média. Podemos olhar para o intervalo de HPDI de \(89\%\) no qual essa valores estão entre \(-0.36\) e \(0.26\).
Talvez exista algum efeito, ou talvez não tenha nenhum efeito dependendo da direção. Nós apenas não sabemos muito bem o que pensar sobre essa variável, pois ela não apresenta uma relação consistente, não existe uma associação consistente na regressão multipla entre a taxa de casamentos e a taxa de divórcios.
Agora, a mediana das idades do casamentos tem uma estimativa média de \(-0.6\) com o desvio padrão também de \(0.16\), temos que a massa da posteriori está inteiramente abaixo de zero! Assim, realmente temos uma associção negativa entre a media das idades dos casasmentos e a taxa de divórcios.
Mas agora nós já sabemos que não temos um impacto diretamente causal entre taxa de casamentos e a taxa de divórcios. Isso estava mascarado pois idade mediana é uma causa comum entre as duas outras variáveis.
# Legendas
# ===========
# beta_2 == D ~ A
# beta_A ==> D ~ A + M
# beta_M ==> D ~ A + M
# beta_1 ==> D ~ M
vars_all = ['beta_1', 'beta_M', 'beta_2', 'beta_A']
describe_posteriori(vars_all, 0.945, plot=True)
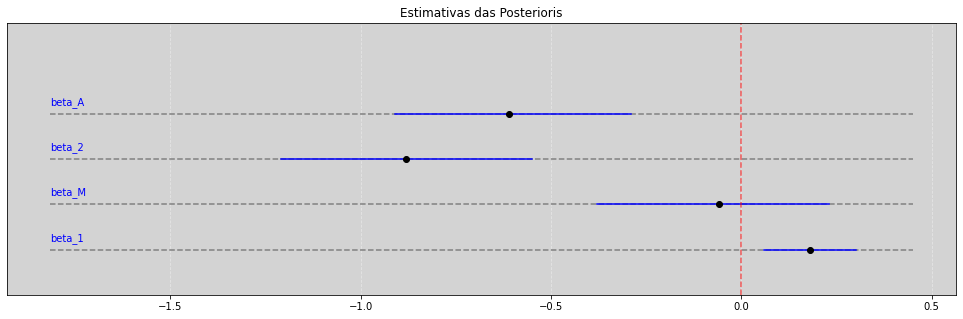
| Mean | Std | 5.5% | 94.5% | |
|---|---|---|---|---|
| beta_1 | 0.18 | 0.06 | 0.06 | 0.30 |
| beta_M | -0.06 | 0.16 | -0.38 | 0.23 |
| beta_2 | -0.88 | 0.18 | -1.21 | -0.55 |
| beta_A | -0.61 | 0.16 | -0.91 | -0.29 |
Quando observando as tabelas acima e comparando com o gráfico, temos que a taxa de casamentos (\(\beta_M\)), resultante da regressão multipla, tem a sua distribuição à posteriori, com \(89\%\) de HPDI, contendo o zero. Portanto provávelmente a variável taxa de casamento (\(\beta_M\)) não tem impacto casual direto na taxa de divórcio.
Ele foi mascarado por que a mediana das idades dos casamentos (\(A\)) é uma variável que influência tanto a taxa de divórcio quanto a taxa de casamentos.
No gráfico acima fica claro que o modelo beta_1, no modelo \(D ~ M\), nos diz que taxa de casamento tem uma associação positiva com a taxa de divórcio, o que era de se esperar pelos nossos entendimentos sobre como poderia funcionar esse evento.
Entretanto, como a regressão múltipla podemos ver que a posteriori atinge o zero, e assim não podemos perceber que provavelmente não existe uma associação entre a taxa de casamentos e a taxa de divórcios.
Isso é uma boa coisa que a regressão múltipla pode fazer por nós! Eu acredito que essa é realmente a relação causal que temos aqui.
Assim, nosso DAG provavelmente seria dessa forma:
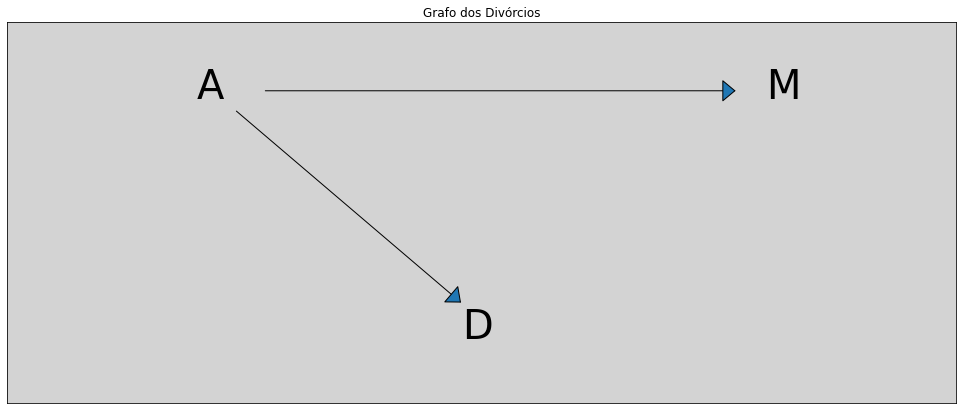
Assim, como não temos uma relação forte da taxa de casamentos (\(M\)) com a variável taxa de divórcios (\(D\)), a representação de nosso DAG, ou seja, a representação da causalidade, poderá ser mapeada de acordo com o gráfico acima.
Mas vamos explorar um pouco melhor o significado dessa abordagem.
Regressão Múltipla¶
Uma vez que nós conhecemos \(A\), mediana das idades dos casamentos, existe apenas um pequeno valor adicional de conhecimento sobre \(D\) que está contido em \(M\), a taxa de casamento.
Então podemos interpretar isso da seguinte forma, ao conhecermos os valores de \(A\) implica que o conhecimento de \(M\) não vai nos ajudar muito mais a entender \(D\). Isso coincide com DAG acima, onde não há relação causal da taxa de casamentos para a taxa de divórcios.
Uma vez que nós conhecemos a \(M\), taxa de casamentos, há muito valor em conhecer também \(A\), mediana das idades dos casamentos.
Isso funciona na outra direção, pois a mediana das idades dos casamentos (\(A\)) é uma causa comum da taxa de casamentos (\(M\)).
Se nós não conhecermos a mediana das idades dos casamentos (\(A\)) em algum estado, ainda é útil conhecer a taxa de casamentos (\(M\)).
Saber sobre a taxa de casamentos (\(M\)) é útil e importante pois isso pode nos dá informações adicionais. Essa informação vem de outra relação causal e não nos dá uma informação causal direta entre as variáveis.
Note
Esse é nosso negócio aqui. A inferência! Descobrir a diferença entre essas coisas.
Se nós apenas quisermos fazer uma previsão e não nos importarmos com a inferência causal, a taxa de casamento é útil e ajudará a prever as coisas. Mas, por outro lado, não nos ajuda a fazer interevenções no mundo real, porque se quisermos mudar a taxa de divórcios (\(D\)) nos estado manipulando a taxa de casamento (\(M\)) não teria nenhum efeito.
Simplesmente por que não é assim que as coisas funcionam. A maquinaria de causalidade natural dos divórcios não apresenta essa ligação entre da taxa de casamentos para a taxa de divórcios.
Assim, para efeito de políticas públicas, é necessário focar nas alterações na mediana da idade dos casamentos (\(M\)) para verificar os efeitos na taxa de divórcios (\(D\)).
Assim precisamos ser claros se queremos apenas prever as coisas. Se quisermos também inteferir as relações causais, devemos fazer a previsão das relações causais para que possamos fazer as intervenções. Uma intervenção requer um verdadeiro entendimento da causalidade do sistema.
Warning
Uma previsão não tem o poder de fazer tais intervenções causais.
Isso é o grande terror da ciência, podemos fazer previsões realmente boas sem entendermos nada! Lembra dos modelos geocêntricos. Modelo estatísticos corretos não são suficientes para descobrir relações causais, então precisamos de algo extra!
Predição da Posteriori¶
Como visualizamos os modelos como este acima? Existem muitas diferentes formas de mostrar isso. Vamos ver algumas formas e exemplos rapidamente. Porém a maneira mais útil de visualizar um particular modelo depende do modelo em particular e do objeto de estudo que estamos tentando observar. Não existe uma forma genérica para visualizar qualquer tipo de gráfico.
Vamos apresentar alguns exemplos:
Plot dos resíduos dos preditores: Muito útil para entender como a regressão funciona, assim iremos fazer isso apenas uma vez nesse curso. Esse tipo de visualização é muito bom para entender o funcionamento da regressão mas não é tão bom para comunicar os resultados.
Plot contrafactuais: Chama-se contrafactuais pois nós imaginamos como manipular qualquer uma das variáveis sem alterar quaisquer outras variárveis. Com isso faremos as previsões para saber como o modelo se comporta com essas manipulações.
Plot da Predição da Posteriori: É basicamente o mesmo que já fizemos antes, porém veremos alguns pontos diferentes mais adiante.
Plot dos Resíduos dos Preditores¶
Objetivo: Mostrar a associação de cada um dos preditores com o resultado, “controlado” por outras preditores.
A associação de uma variável com o resultado parece ter o controle em outras variáveis preditoras, então dentro da maquinaria do modelo. Queremos com isso entender como o modelo enxerga essas coisas internamente. Isso é o que queremos fazer, calcular esses estados intermediários mesmo que eles não sejam visíveis no modelo, para termos uma boa intuição do que está acontecendo internamente no modelo.
Nos dá uma intuição muito boa.
Útil para termos uma intuição do modelo e como está o seu funcionamento interno.
Nunca analise os resíduos.
Não existem motivos lógicos para fazer uma regressão da variável resposta, (\(D \sim residuos\), por exemplo), isso nos dá uma resposta errada. Pois nos dará estimativas erradas e tendênciosas.
Receita:
Faça uma regressão de uma variável com as outras variáveis.
No nosso exemplo, teremos a idade mediana dos casamentos, (\(M\)) explicando a taxa de casamento, (\(A\)), ambas padronizadas.
Calcule os resíduos dos preditores.
Assim podemos encontrar a variância extra que sobrou depois dessa associação, esses são os resíduos.
Faça uma regressão da variáveis resposta com os resíduos encontrados no passo anterior.
# =============================================
# Lendo os dados da Waffle House (novamente)
# =============================================
df = pd.read_csv('./data/WaffleDivorce.csv', sep=';')
df.head()
| Location | Loc | Population | MedianAgeMarriage | Marriage | Marriage SE | Divorce | Divorce SE | WaffleHouses | South | Slaves1860 | Population1860 | PropSlaves1860 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alabama | AL | 4.78 | 25.3 | 20.2 | 1.27 | 12.7 | 0.79 | 128 | 1 | 435080 | 964201 | 0.45 |
| 1 | Alaska | AK | 0.71 | 25.2 | 26.0 | 2.93 | 12.5 | 2.05 | 0 | 0 | 0 | 0 | 0.00 |
| 2 | Arizona | AZ | 6.33 | 25.8 | 20.3 | 0.98 | 10.8 | 0.74 | 18 | 0 | 0 | 0 | 0.00 |
| 3 | Arkansas | AR | 2.92 | 24.3 | 26.4 | 1.70 | 13.5 | 1.22 | 41 | 1 | 111115 | 435450 | 0.26 |
| 4 | California | CA | 37.25 | 26.8 | 19.1 | 0.39 | 8.0 | 0.24 | 0 | 0 | 0 | 379994 | 0.00 |
# ==========================================
# Relembrando: Padronizando as variáveis
# ==========================================
M_stdr = (df.Marriage - df.Marriage.mean())/df.Marriage.std()
D_stdr = (df.Divorce - df.Divorce.mean())/df.Divorce.std()
A_stdr = (df.MedianAgeMarriage - df.MedianAgeMarriage.mean())/df.MedianAgeMarriage.std()
Para evitar a reescrever muito código, irei ao longo do texto criando alguns funções para facilitar a leitura.
Segue abaixo a primeira função, ela irá plotar uma priori para um modelo linear normalmente distribuído.
# ===================
# Plotando a priori
# ===================
def plot_priori_lm_normal(N, alpha, beta):
"""
Plot à priori to linear model using normal distribution.
Modelo:
=======
y ~ normal(mu_i, sigma)
mi = alpha + beta * x
Prioris:
========
alpha ~ normal(alpha[alpha_mean], alpha[alpha_std], N)
beta ~ normal(beta[beta_mean], beta[beta_std], N)
sigma ~ exponential(1)
Params:
=======
N: int
alpha: [alpha_mean, alpha_std]
beta: [beta_mean, beta_std]
"""
# Prioris
alpha = np.random.normal(alpha[0], alpha[1], N)
beta = np.random.normal(beta[0], beta[1], N)
# Os dados originais estão padronizados
x = np.linspace(-3, 3, 100)
# Modelo linear para as prioris
y = [alpha + beta * x_i for x_i in x]
# Plotando a priori
plt.figure(figsize=(17,9))
plt.plot(x, y, color='darkblue', linewidth=0.1)
plt.title('Plot das Prioris normalizadas')
plt.xlabel('(x) - Eixo X')
plt.ylabel('(y) - Eixo y')
plt.xlim((-3, 3))
plt.ylim((-3, 3))
plt.grid(ls='--', color='white', alpha=0.4)
plt.show()
Abaixo, a função irá encapsular todo o código de uma regressão linear bayesiana univariada.
# ================================
# Regressão Linear - Univariada
# ================================
def plot_lm_posteriori(var_y, var_x, alpha, beta, N=200, plot_residuos=True,
title_xaxis=False, title_yaxis=False):
# Modelo linear para as prioris
# Os dados originais estão padronizados
# Os dados originais estão padronizados
x = np.linspace(-3, 3, 100)
# Cáculo dos y e y_mean dado x
y = [alpha + beta * x_i for x_i in x]
y_mean = alpha.mean() + beta.mean() * x
# Plotando a priori
plt.figure(figsize=(17,9))
plt.plot(x, y, color='darkblue', linewidth=0.1, alpha=0.5)
plt.plot(x, y_mean, color='black', linewidth=2)
plt.plot(var_x, var_y, 'o', color='red', markersize=5)
if plot_residuos:
plt.plot([var_x, var_x],
[var_y, alpha.mean() + beta.mean() * var_x],
'-', markersize=3, color='darkred', alpha=0.3)
plt.title('Posteriori Plot dos Resíduos dos Preditores')
plt.xlabel(title_xaxis if title_xaxis else '(x) - Eixo x')
plt.ylabel(title_yaxis if title_yaxis else '(y) - Eixo y')
plt.xlim((-3, 3))
plt.ylim((-3, 3))
plt.grid(ls='--', color='white', alpha=0.4)
plt.show()
def lm(var_y, var_x, alpha, beta, exp=1, num_chains=4, filter_n=500, num_samples=5000, plot=True,
plot_residuos=True, title_xaxis=False, title_yaxis=False):
if not (len(var_x) == len(var_y)): # TODO: Use except to raise an error.
print('Erro: As dimensões das variáveis não são iguais.')
return False
stan_model = """
data {
int<lower=0> N;
vector[N] variavel_resposta;
vector[N] variavel_explicativa;
real alpha_mean;
real alpha_std;
real beta_mean;
real beta_std;
real exp;
}
parameters {
real alpha;
real beta;
real<lower=0> sigma;
}
model {
alpha ~ normal(alpha_mean, alpha_std);
beta ~ normal(beta_mean, beta_std);
sigma ~ exponential({exp});
variavel_resposta ~ normal(alpha + beta * variavel_explicativa, sigma);
}
"""
data = {
'N': len(var_y),
'variavel_resposta': var_y,
'variavel_explicativa': var_x,
'alpha_mean': alpha[0],
'alpha_std': alpha[1],
'beta_mean': beta[0],
'beta_std': beta[1],
'exp': exp,
}
posteriori = stan.build(stan_model, data=data)
fit = posteriori.sample(num_chains=num_chains, num_samples=num_samples)
alpha_ = fit['alpha'].flatten()
beta_ = fit['beta'].flatten()
# Filtra a quantidade de dados para o plot
if filter_n > 0:
alpha_ = alpha_[len(alpha_) - filter_n: ]
beta_ = beta_[len(beta_) - filter_n: ]
if plot:
plot_lm_posteriori(var_y, var_x, alpha_, beta_, plot_residuos=plot_residuos,
title_xaxis=title_xaxis, title_yaxis=title_yaxis)
residuos = var_y - (alpha_.mean() + beta_.mean() * var_x)
return alpha_, beta_, residuos
# ====================================
# Plotando a priori para verificar
# ====================================
# Prioris
alpha_divorce = [0, 0.3]
beta_divorce = [0, 0.4]
N = 200
# Plot da Priori - Modelo linear
plot_priori_lm_normal(N, alpha_divorce, beta_divorce)
# ==================
# Posteriori M ~ A
# ==================
posteriori_MA = lm(var_y=M_stdr.values, var_x=A_stdr.values, alpha=alpha_divorce, beta=beta_divorce,
title_yaxis= "Taxa de casamentos (M)",
title_xaxis= "Mediana das Idades dos Casamentos (A)")
# =============================
# Posteriori D ~ residuos_MA
# =============================
residuos_MA = posteriori_MA[2]
posteriori_MA = lm(D_stdr.values, residuos_MA, alpha_divorce, beta_divorce, plot_residuos=False,
title_xaxis="Taxa de Divórcio (D)",
title_yaxis="Resíduos da Taxa de Casamentos (A-residual)")
# ===================
# Posteriori A ~ M
# ===================
posteriori_AM = lm(var_y=A_stdr.values, var_x=M_stdr.values, alpha=alpha_divorce, beta=beta_divorce,
title_yaxis= "Mediana das Idades dos Casamentos (A)",
title_xaxis= "Taxa de casamentos (M)")
# =============================
# Posteriori D ~ residuos_AM
# =============================
residuos_AM = posteriori_AM[2] # Resíduos
# posteriori_AM = lm(D_stdr.values, residuos_AM, alpha_divorce, beta_divorce, plot_residuos=False)
posteriori_AM = lm(D_stdr.values, residuos_AM, alpha_divorce, beta_divorce, plot_residuos=False,
title_xaxis="Taxa de Divórcio (D)",
title_yaxis="Resíduos da Idade da Mediana dos Casamentos (M-residual)")
Podemos observar que nos gráficos acima (o (\(2^o\)) gráfico Posteriori D ~ residuos_MA e o (\(4^o\)) gráfico Posteriori D ~ residuos_AM) que a regressão dos seus respectivos resíduos explicando a taxa de divórcio.
Existe uma forte correlação negativa no gráfico Posteriori D ~ residuos_AM, o que já ocorre no gráfico Posteriori D ~ residuos_MA. Isso ocorre por que assim existe um valor considerável
da taxa de casamentos (M) que explica
(TODO: Comparar com a aula, 38:01 - Parece que estão invertidos.)
‘Controles’ estatísticos¶
Quando pensamos em controles estatíticos, já nos vem a mente os Designs de Experimentos, no qual configuramos quais as variáveis são possívelmente causas nos estudos observados. Não fazemos isso, não há nada ético que indique que taxa de casamento (\(M\)) é causa de algo. Isso não é ético com as outras pessoas nem conosco fazer essas coisas.
Então, nós estávemos presos a estudos observacionais para uma quantidade muito grande de problemas importantes e o que nós queremos fazer é inferencias causais no entanto, e as regressões múltiplas nos oferecem uma forma para fazer isso, apenas quando combinamos com uma ideia clara sobre quais são as relações causais entre os modelos.
Controle estatístico significa condicionar apenas as informações em uma variável e verificar se existe alguma informação valiosa!
Mas, para interpretar o efeito o efeito que acontece apartir desses controles é necessário um framework, ou seja, uma estrutura adequada tal como os DAGs ou qualquer outra coisa. Iremos ver exemplos que ao controlar algo estamos na verdade criando um confound (uma confusão). Podemos criar confound tanto quanto removê-los, nesse caso iremos remover achando que iremos ter uma resposta certa, mais tarde.
Regressão linear múltipla responde a questão: O quão cada preditor está associado com o resultado, uma vez que conhecemos TODOS os outros preditores?
Usamos modelo para construir a saída esperada - não mágica!
Não ser arrogante: A taxa de casamento ainda pode estar associada com a taxa de divórcio para algum subconjunto de estados.
Não podemos fazer uma forte inferência causal apenas com as médias, é preciso os dados indivíduais.
Gráficos contrafactuais¶
Os gráfico contrafactuais são mostrados quando mantemos todas as variáveis fixas e manipulamos apeans uma variável de interesse. Assim, veremos a linha de regressão mudando seu comportamento.
O objetivo é explorar as implicações dos resultados do modelo.
- Fixar os outros preditores
- Calcular a predição através do valor dos preditores
Nos gráficos vemos como o modelo vê as coisa internamente, ou seja, como ele vê as relações preditivas, assumindo que podemos brincar de Deus e definir os valores preditos para qualquer relação. Claro, qualquer relação que não esteja no mundo real.
Manipular uma dessas variáveis também irá manipular os valores das outras variáveis. Assim, se manipularmos a idade mediada dos casamentos também estaremos manipulando a taxa de casamento. Porém o contrário não é verdadeiro.
Com esses gráficos podemos definir qualquer valor que goste e ver como o modelo irá reagir a essa alteração. Isso é muito útil para saber o acontece no modelo, mas isso ainda não é inferencia causal.
Checagem da predição da posteriori¶
Objetivo: Calcular as predições implicíta para os casos observados.
Checar o ajuste do modelo - golems podem cometer erros.
Encontrar falhas na modelagem, estimular novas ideias.
Para saber a aproximação da posteriori funcionou corretamente. As vezes os ajustes da posteriori nos diram que o ajuste está muito ruim entre as previsões posteriores do modelo e os dados brutos. Isso que iremos fazer, comparar esses dois conjuntos de dados, se forem semelhantes, nós podemos ter errado algo, nosso computador pode ter errado algo ou ambos.
Precisamos rever e ajustar, as estimativas dos modelos podem estar erradas pois as vezes a natureza do modelo é complicada deixando um ambiente hostil para vida humana e temos que lutar para existir, lutando contra a entropia.
Sempre sobre a média da distribuição posteriori.
Usar apenas a média da posteriori nos leva a excesso de confiança.
Abraçar a incerteza.
A outra coisa que podemos fazer é olhar para os casos que não se encaixam muito bem e tentar descobrir como fazer inferências causais mais robustas.
def plot_comparative_obseved_posteriori():
list_compared = []
# Para ficar parecido com os resutados da aula, usar o credible_mass menor que 0.68 (muito demorado!)
for i in range(len(M_stdr.values)):
predict_divorce = np.random.normal(alpha_check + beta_M_check * M_stdr.values[i] + beta_A_check * A_stdr.values[i], sigma_check[i])
hpdi = HPDI(predict_divorce, credible_mass=0.89)
mean_posteriori = np.mean(predict_divorce)
list_compared.append([D_stdr.values[i], mean_posteriori, hpdi[0], hpdi[1]])
list_compared = pd.DataFrame(list_compared, columns=['Observed', 'Predicted', 'HPDI_min', 'HPDI_max'])
plt.figure(figsize=(17, 9))
# Plot mean
plt.plot(list_compared.Observed, list_compared.Predicted, 'o', ms=7)
for i in range(len(list_compared)):
plt.plot([list_compared.Observed[i], list_compared.Observed[i]],
[list_compared.HPDI_min[i], list_compared.HPDI_max[i]],
lw=0.4, color='blue')
plt.plot(np.linspace(-2, 2), np.linspace(-2, 2), '--', color='darkblue', linewidth=3, alpha=0.5)
plt.title('Valores da predição comparada com o observado')
plt.xlabel('Divórcio Observado')
plt.ylabel('Divórcio Predito')
plt.grid(ls='--', color='white', linewidth=0.4)
plt.show()
plot_comparative_obseved_posteriori()
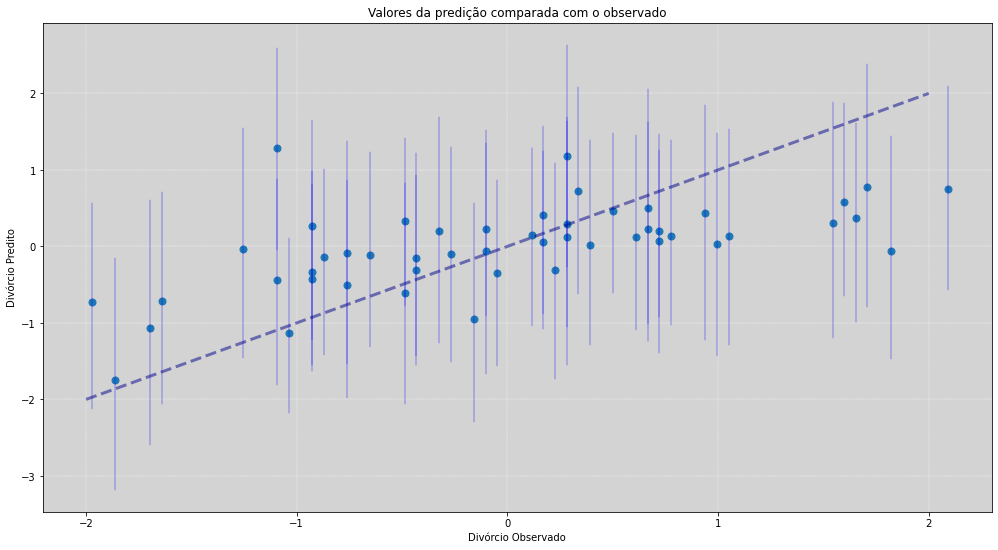
O gráfico acima irá comparar os valores preditos contidos na posteriori com os valores observados. Para cada um dos estados, calculamos o intervalo de \(89\%\) de credibilidade (HPDI) e sua média.
A linha tracejada é a identidade. Para estados que tem a média em cima da linha, temos um ajuste perfeito. Já para estados longe dessa linha, como o estado ID (Idaho) o valor predito falha!
Uma das possíveis explicações do porque estamos prevendo altos valores na taxa de divóricos em um estado que temos como evidência uma taxa bem mais baixa é, a grande presença de frequentadores da A Igreja de Jesus Cristo dos Santos dos Últimos Dias, conhecidos como os Mórmons. Casamentos de pessoas dessa religião tendem a serem mais duradouros por seus motivos religiosos.
{kind=link}
Mas para outros estados que estão mal ajustados, é necessário olhar mais de perto e entender melhor o que está acontecendo.
Associações Mascaradas¶
Vamos ver outra coisa interessante que a regressão pode fazer. Uma delas é conseguir revelar as correlações espúrias, como acabamos de ver na sessão anterior, com a estratificação dos controles estatísticos.
Outra coisa interessante é a de que quando temos 2 preditores influenciando na variável resposta, cada em diferentes direções, eles acabam mascarando um ao outro. Precisamos saber qual o real efeito total da causalidade, chamamos isso de associação mascarada.
As vezes a associação entre o resultado e o preditor pode ser mascarada por uma outra variável.
Necessitamos de ambos preditores para ver a sua influência causal.
Tende a surgir quando:
Outro preditor associado com a resposta que atua na direção oposta.
Ambos os preditores tem uma associação entre si.
E como consequência, na natureza eles escondem o efeito um dos outros. E, se não medirmos ambos, podemos ser levados a acreditar que nenhum dele importa tanto quando realmente importam.
Ruído nos preditores também poderá mascarar a associação (residuals confounding).
Outro tipo de associação mascarada é quando ocorre que nossas medidas contém muitos erros, assim podemos não ver qual o efeito real que está acontecendo.
Milk and Brain¶

Dados pode ser encontrado aqui
Na imagem acima temos três primatas, um lêmure e dois macacos.
Estamos interessado, com esse conjunto de dados, em saber a associação que existe entre a energia do leite (\(\frac{Kcal}{gramas}\)), quão energético é o leite que chegam aos seus filhotes e quão inteligente (\(\%\) neocortex) cada primata é, usando como particular método de metrificação de inteligência, qual o percentual do neocortex em relação a todo o cérebro).
Uma das hipótese que temos é que, para primatas que sejam mais inteligentes, é necessário maior quantidade de energia no leite materno.
# =======================
# Milk and Brain - Data
# =======================
milk_full = pd.read_csv('./data/milk.csv', sep=';')
milk_full
| clade | species | kcal.per.g | perc.fat | perc.protein | perc.lactose | mass | neocortex.perc | |
|---|---|---|---|---|---|---|---|---|
| 0 | Strepsirrhine | Eulemur fulvus | 0.49 | 16.60 | 15.42 | 67.98 | 1.95 | 55.16 |
| 1 | Strepsirrhine | E macaco | 0.51 | 19.27 | 16.91 | 63.82 | 2.09 | NaN |
| 2 | Strepsirrhine | E mongoz | 0.46 | 14.11 | 16.85 | 69.04 | 2.51 | NaN |
| 3 | Strepsirrhine | E rubriventer | 0.48 | 14.91 | 13.18 | 71.91 | 1.62 | NaN |
| 4 | Strepsirrhine | Lemur catta | 0.60 | 27.28 | 19.50 | 53.22 | 2.19 | NaN |
| 5 | New World Monkey | Alouatta seniculus | 0.47 | 21.22 | 23.58 | 55.20 | 5.25 | 64.54 |
| 6 | New World Monkey | A palliata | 0.56 | 29.66 | 23.46 | 46.88 | 5.37 | 64.54 |
| 7 | New World Monkey | Cebus apella | 0.89 | 53.41 | 15.80 | 30.79 | 2.51 | 67.64 |
| 8 | New World Monkey | Saimiri boliviensis | 0.91 | 46.08 | 23.34 | 30.58 | 0.71 | NaN |
| 9 | New World Monkey | S sciureus | 0.92 | 50.58 | 22.33 | 27.09 | 0.68 | 68.85 |
| 10 | New World Monkey | Cebuella pygmaea | 0.80 | 41.35 | 20.85 | 37.80 | 0.12 | 58.85 |
| 11 | New World Monkey | Callimico goeldii | 0.46 | 3.93 | 25.30 | 70.77 | 0.47 | 61.69 |
| 12 | New World Monkey | Callithrix jacchus | 0.71 | 38.38 | 20.09 | 41.53 | 0.32 | 60.32 |
| 13 | New World Monkey | Leontopithecus rosalia | 0.71 | 36.90 | 21.27 | 41.83 | 0.60 | NaN |
| 14 | Old World Monkey | Chlorocebus pygerythrus | 0.73 | 39.17 | 14.65 | 46.18 | 3.47 | NaN |
| 15 | Old World Monkey | Miopithecus talpoin | 0.68 | 40.15 | 18.08 | 41.77 | 1.55 | 69.97 |
| 16 | Old World Monkey | M fuscata | 0.72 | 53.05 | 13.00 | 33.95 | 7.08 | NaN |
| 17 | Old World Monkey | M mulatta | 0.97 | 55.51 | 13.17 | 31.32 | 3.24 | 70.41 |
| 18 | Old World Monkey | M sinica | 0.79 | 48.90 | 13.91 | 37.19 | 7.94 | NaN |
| 19 | Old World Monkey | Papio spp | 0.84 | 54.31 | 10.97 | 34.72 | 12.30 | 73.40 |
| 20 | Ape | Nomascus concolor | 0.48 | 15.96 | 12.52 | 71.52 | 7.59 | NaN |
| 21 | Ape | Hylobates lar | 0.62 | 34.51 | 12.57 | 52.92 | 5.37 | 67.53 |
| 22 | Ape | Symphalangus syndactylus | 0.51 | 26.42 | 13.46 | 60.12 | 10.72 | NaN |
| 23 | Ape | Pongo pygmaeus | 0.54 | 37.78 | 7.37 | 54.85 | 35.48 | 71.26 |
| 24 | Ape | Gorilla gorilla gorilla | 0.49 | 27.18 | 16.29 | 56.53 | 79.43 | 72.60 |
| 25 | Ape | G gorilla beringei | 0.53 | 30.59 | 20.77 | 48.64 | 97.72 | NaN |
| 26 | Ape | Pan paniscus | 0.48 | 21.18 | 11.68 | 67.14 | 40.74 | 70.24 |
| 27 | Ape | P troglodytes | 0.55 | 36.84 | 9.54 | 53.62 | 33.11 | 76.30 |
| 28 | Ape | Homo sapiens | 0.71 | 50.49 | 9.84 | 39.67 | 54.95 | 75.49 |
# ================
# Descrições
# ================
milk_full.describe()
| kcal.per.g | perc.fat | perc.protein | perc.lactose | mass | neocortex.perc | |
|---|---|---|---|---|---|---|
| count | 29.000000 | 29.000000 | 29.000000 | 29.000000 | 29.000000 | 17.000000 |
| mean | 0.641724 | 33.990345 | 16.403448 | 49.606207 | 14.726897 | 67.575882 |
| std | 0.161402 | 14.286670 | 4.846878 | 14.055174 | 24.770469 | 5.968612 |
| min | 0.460000 | 3.930000 | 7.370000 | 27.090000 | 0.120000 | 55.160000 |
| 25% | 0.490000 | 21.220000 | 13.000000 | 37.800000 | 1.620000 | 64.540000 |
| 50% | 0.600000 | 36.840000 | 15.800000 | 48.640000 | 3.470000 | 68.850000 |
| 75% | 0.730000 | 46.080000 | 20.770000 | 60.120000 | 10.720000 | 71.260000 |
| max | 0.970000 | 55.510000 | 25.300000 | 71.910000 | 97.720000 | 76.300000 |
# =====================
# Filtrando os dados
# =====================
milk = milk_full[['kcal.per.g', 'neocortex.perc']].copy()
milk['log(mass)'] = np.log(milk_full[['mass']])
milk.head()
| kcal.per.g | neocortex.perc | log(mass) | |
|---|---|---|---|
| 0 | 0.49 | 55.16 | 0.667829 |
| 1 | 0.51 | NaN | 0.737164 |
| 2 | 0.46 | NaN | 0.920283 |
| 3 | 0.48 | NaN | 0.482426 |
| 4 | 0.60 | NaN | 0.783902 |
# =====================
# Leite dos Primatas
# =====================
pd.plotting.scatter_matrix(milk[['kcal.per.g', 'log(mass)', 'neocortex.perc']],
figsize=(17, 9), marker='o', color='red',
hist_kwds={'bins': 20, 'rwidth': 0.9, 'color': 'red', 'alpha': 0.1},
s=100)
plt.show()
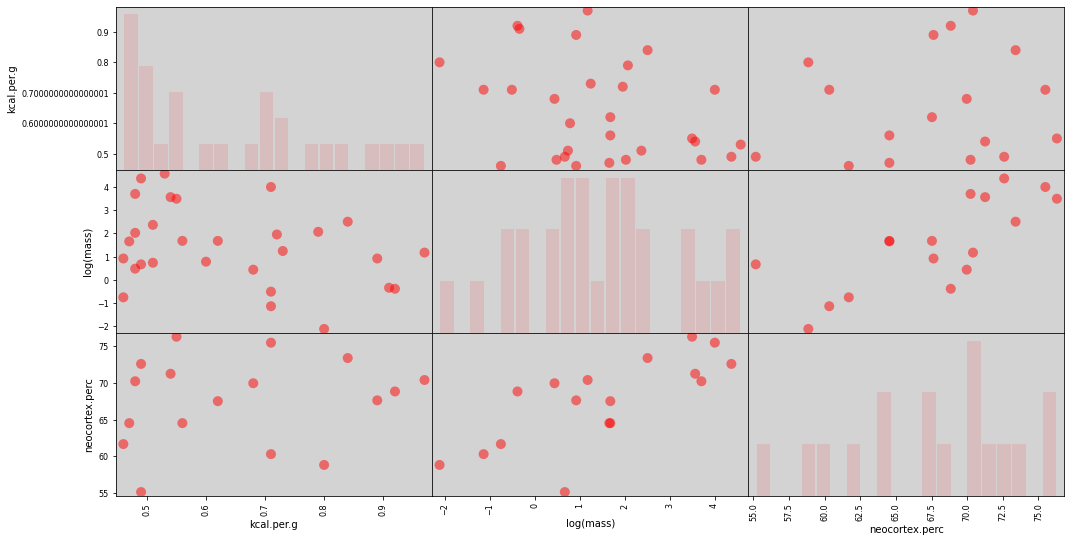
O que vemos aqui é uma forte correlação positiva entre o \(\%\) neocortex e a magnetude da massa. Ou seja, quanto mais massa o primata tiver, maior também será o percentual do seu cortex, e não apenas o cérebro como um todo.
A seguir vamos fazer a regressão entre essas duas variáveis.
52:51
No próximo capítulo, iremos descrever apenas os códigos.
Comecei a ler o livro do início e todas as explicações a seguir podem ser encontradas no próprio livro.
Como dito anteriormente, esse material irá fornecer todos os códigos em linguagem \(Python3\) usando diretamente a biblioteca \(Stan\) em conjunto com a wrapper \(PyStan\).
Para usuários do \(R\), exite um Wrapper para \(RStan\) para uma possível codificação sem utilizar a biblioteca \(Rethinking\) do próprio livro.
Dúvidas ou sugestões acesse a parte inicial desse material para entrar em contato.